
高岡智則
年齢:33歳 性別:男性 職業:Webディレクター(兼ライティング・SNS運用担当) 居住地:東京都杉並区・永福町の1LDKマンション 出身地:神奈川県川崎市 身長:176cm 体系:細身〜普通(最近ちょっとお腹が気になる) 血液型:A型 誕生日:1992年11月20日 最終学歴:明治大学・情報コミュニケーション学部卒 通勤:京王井の頭線で渋谷まで(通勤20分) 家族構成:一人暮らし、実家には両親と2歳下の妹 恋愛事情:独身。彼女は2年いない(本人は「忙しいだけ」と言い張る)
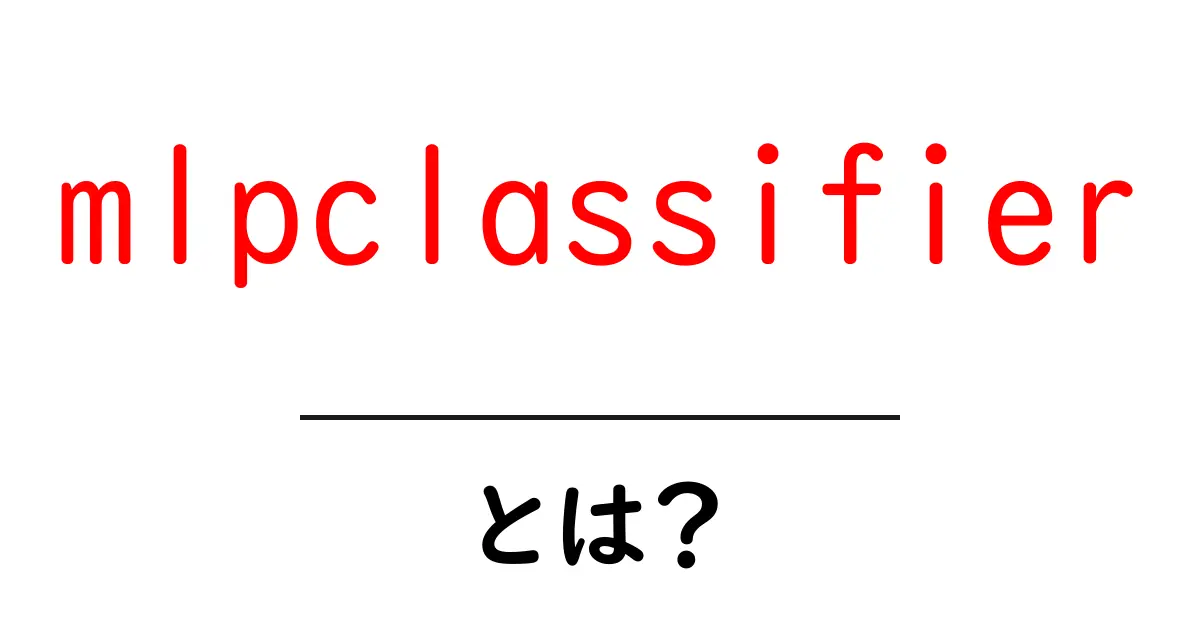
mlp classifier とは?
mlpclassifier とは、機械学習の分野で使われる「多層パーセプトロン」を用いた分類器のことです。mlpclassifier は図で表すと複数の層を重ねたニューラルネットの一種で、入力データを学習して「どのクラスに属するか」を判断します。scikit-learn という人気の機械学習ライブラリには MLPClassifier というクラスがあり、これを使うと比較的手軽にモデルを作ることができます。英語の公式名称は MLPClassifier ですが、日本語の解説では mlpclassifier という表記でも呼ばれます。初心者の人には「ニューラルネットって難しそう」という印象がありますが、mlpclassifier の基本はシンプルな考え方です。
仕組みと学習の流れ
mlpclassifier は input から始まり、複数の層を通じて情報を伝搬させます。層ごとに重みが更新され、最終的に出力層で各クラスの確率やスコアを出します。学習には誤差逆伝搬法と呼ばれるアルゴリズムを使い、データが増えるほどモデルは正確になります。活性化関数 や 最適化アルゴリズム の影響を受け、適切な設定が必要です。
初期設定と使い方
使い方の基本は次の流れです。1) 学習用データとテストデータを準備する。2) モデルを作成する。3) 学習させる。4) テストデータで評価する。データ前処理としては欠損値の処理や標準化が重要です。特徴量の標準化 を行うと学習が安定します。
実際のコードの代わりに、使い方のイメージを文章で説明します。まずデータ X とラベル y を用意します。次に sklearn の MLPClassifier を使って model を作り、hidden_layer_sizes を設定して学習を開始します。例のイメージは以下のとおりです。ただし実際にはコードブロックを使って学習しますが、ここでは文章で表現します。mlpclassifier は fit で学習し、predict で新しいデータを分類します。
パラメータの解説
mlpclassifier の挙動は設定次第で大きく変わります。以下は代表的なパラメータとその意味です。
| パラメータ | 説明 | おすすめの設定 |
|---|---|---|
| hidden_layer_sizes | 隠れ層のユニット数をタプルで指定します | (100, 50) など、データ量に応じて調整します |
| activation | 活性化関数を決定します | relu が一般的に使われます |
| solver | 重みの更新アルゴリズムを選択します | adam が使いやすく安定します |
| max_iter | 学習の最大回数を設定します | 300 以上を目安に、データ量に応じて増減 |
| random_state | 乱数の種を設定します | 再現性のため必ず設定しておくと良い |
実例と使いどころ
小さめのデータセットから中規模のデータまで、分類問題の基礎として使うのに適しています。適切な前処理 と パラメータ調整 がうまくいけば、ロジスティック回帰よりも高い精度を出せることがあります。
注意点とよくある質問
データが少ないと過学習しやすく、訓練時間が長くなることがあります。データを増やすか、正則化 の方法を取り入れると良いです。モデルの複雑さと学習時間のトレードオフを理解することが大切です。
まとめ
mlpclassifier は初心者にも扱える強力な分類器 です。正しく使えば、複雑なデータのパターンを捉え、分類精度を向上させることができます。初めは小さなデータで練習し、パラメータを少しずつ変えながら理解を深めていくのがコツです。
mlpclassifierの同意語
- 多層パーセプトロン分類器
- 複数の層を持つパーセプトロンを用いてデータを分類する機械学習モデル。scikit-learn の MLPClassifier を指すことが多い表現です。
- MLP分類器
- MLP(多層パーセプトロン)を用いたデータ分類器の総称。単純に「MLP」を使って分類するモデルを指します。
- MLPClassifier
- scikit-learn に実装されているクラス名。多層パーセプトロンを用いた分類器そのものを指します。
- 多層パーセプトロンモデル
- 同じ概念のモデル表現。複数の層からなるニューラルネットワークを用いた分類モデルです。
- 多層ニューラルネットワーク分類器
- MLP の別名。多層のニューラルネットワークを使って入力データをカテゴリに分類します。
- sklearn の MLPClassifier
- Python の機械学習ライブラリ scikit-learn に実装された MLPClassifier の呼び方の一つです。
- Multi-layer Perceptron (MLP) の分類器
- 英語名の説明表現。多層パーセプトロンを用いた分類機を指します。
mlpclassifierの対義語・反対語
- MLPRegressor(多層パーセプトロン回帰器)
- MLPClassifierの対義。分類ではなく回帰を行うモデル。出力は連続値で、カテゴリを予測する代わりに数値を推定します。学習の枠組みはニューラルネット同士ですが、目的が異なります。
- 線形分類器(例: ロジスティック回帰、線形SVM)
- 1直線(または平面)でクラスを分けるタイプのモデル。MLPClassifierが扱う非線形境界に対して、線形境界しか作れません。特徴量が線形分離できる場合に有効です。
- 単層パーセプトロン
- 最も基本的なニューラルネット。1層だけで線形境界を作るため、非線形な分離は難しく、MLPClassifierより表現力が限定されます。
- 決定木分類器
- 特徴を順次分割して木構造を作る分類器。解釈性が高く、非線形の境界を直感的に表現できます。ニューラルネットとは独立したアルゴリズムです。
- k近傍分類器(k-NN)
- 新しい点を訓練データの近さで決定する、非パラメトリックな分類手法。学習が軽く始めやすいが、大規模データでは推論コストが高くなることがあります。
- SVM(サポートベクターマシン)[線形・非線形]
- 境界を最大化して分類する強力な手法。線形カーネルなら直線の境界、RBFなどの非線形カーネルを使えば非線形の境界も作れます。ニューラルネットとは別のアルゴリズムです。
- ナイーブベイズ(Naive Bayes)
- 特徴を独立と仮定する確率的分類器。計算は速くシンプルですが、特徴間の依存関係を過度に無視する場合があります。
mlpclassifierの共起語
- scikit-learn
- Python の機械学習ライブラリ。MLPClassifier はこのライブラリに実装されているクラスの一つです。
- multilayer_perceptron
- 多層パーセプトロンの略。複数の層を持つニューラルネットワークの総称で、MLPClassifier が扱うモデルです。
- ニューラルネットワーク
- 人間の脳のニューロンの結合を模した機械学習モデルの総称。MLPClassifier はその一種です。
- 分類
- データを事前に定義されたクラスに割り当てる学習タスク。
- 教師あり学習
- 入力データと正解ラベルを使ってモデルを学習させる枠組み。
- 訓練
- データを使ってモデルのパラメータを調整する学習プロセス。
- fit
- 訓練データを用いてモデルを学習させる scikit-learn のメソッド。
- predict
- 新しいデータのクラスを予測するメソッド。
- predict_proba
- 各クラスの確率を返す予測メソッド。
- 活性化関数
- ニューロンの出力を決定する非線形関数。MLP の各層で使われる。
- relu
- Rectified Linear Unit。正の値はそのまま、負の値は 0 にする活性化関数。
- logistic
- シグモイド関数。出力を確率のように扱える活性化関数。
- tanh
- ハイパボリックタンジェント関数。出力を -1 から 1 の範囲に圧縮。
- identity
- 恒等関数。入力をそのまま出力する活性化関数。
- hidden_layer_sizes
- 隠れ層のユニット数と層の配置を指定するパラメータ。
- solver
- 学習を最適化するアルゴリズム。例: 'adam', 'sgd', 'lbfgs'。
- adam
- 適応的な確率的勾配降下法。大規模データで安定した学習を提供。
- sgd
- 確率的勾配降下法。小分割データを使ってパラメータを更新。
- lbfgs
- 準ニュートン法の一種。小規模データで高速に収束することがある。
- alpha
- L2 正則化の強さ。過学習を抑える役割。
- regularization
- モデルの複雑さを抑制し、汎化性能を高める手法。
- max_iter
- 最大の学習イテレーション回数。
- learning_rate
- 学習の進み方を決める指標。constant/invscaling/adaptive のいずれかを選択。
- learning_rate_init
- 初期の学習率。
- batch_size
- 一度に処理するデータ量。小さくすると更新が頻繁、大きくすると計算安定性が向上。
- early_stopping
- 検証データで性能が改善しなくなった時点で訓練を打ち切る機能。
- validation_fraction
- early_stopping の検証データとして使うデータの割合。
- random_state
- 乱数の種。再現性を確保するために設定する。
- train_test_split
- データを訓練データとテストデータに分割する scikit-learn の関数。
- accuracy
- 正解率。正しく分類されたデータの割合。
- precision
- 適合率。予測が正と判定された中で実際に正解だった割合。
- recall
- 再現率。実際に正解のデータのうち正しく正と判定された割合。
- F1
- 適合率と再現率の調和平均。
- confusion_matrix
- 混同行列。予測結果の正解クラスと予測クラスの組み合わせを表す表。
- pipeline
- 前処理とモデルを連結して一連の処理として扱う機能。
- StandardScaler
- 特徴量を標準化して平均0、分散1に揃える前処理。
- 前処理
- 特徴量の標準化・正規化・エンコーディングなど、学習前のデータ整形。
- 特徴量
- モデルが受け取る説明変数。データの入力。
- データセット
- 学習と評価のためのデータの集合。
- 訓練データ
- モデルを学習させるためのデータ。
- one-hot encoding
- カテゴリ変数を0/1のベクトルに変換する方法。
- ハイパーパラメーターチューニング
- モデルの性能を高めるためにパラメータを調整する作業。
- gridsearch
- すべての組み合わせを網羅的に探索して最適なハイパーパラメータを見つける手法。
- cross_validation
- データを分割して複数回評価し、汎化性能を測る手法。
mlpclassifierの関連用語
- MLPClassifier
- scikit-learn が提供する多層パーセプトロン分類モデルのクラス。ニューラルネットワークを使って分類を行う学習器。
- Multilayer Perceptron
- MLPの正式名称。入力層・1つ以上の隠れ層・出力層から構成される全結合ニューロンネットワークの総称。
- hidden_layer_sizes
- 隠れ層の構成を数値タプルで指定するパラメータ。例: (100,) は1層100ユニット、(50, 25) は2層でそれぞれ50と25のユニット。
- activation
- 各隠れ層の活性化関数を決めるパラメータ。選択肢は 'identity'(線形), 'logistic'(シグモイド), 'tanh', 'relu'。
- solver
- 学習アルゴリズムの種類。'lbfgs'(準ニュートン法), 'sgd'(確率的勾配降下法), 'adam'(Adam最適化)
- alpha
- L2正則化の係数。大きいと過学習の抑制効果が高まるが学習が遅くなることがある。
- batch_size
- 1回の反復で処理するサンプル数。'auto' はデータ量に応じて自動設定。
- learning_rate
- 学習率のスケジュール。'constant'(一定), 'invscaling'(減衰), 'adaptive'(適応的)。
- learning_rate_init
- 初期学習率。一般的には 0.001 など。
- max_iter
- 最大反復回数。データセット全体を何回学習するかを決める。
- shuffle
- 各エポックで訓練データをシャッフルするかどうか。
- random_state
- 乱数シード。結果の再現性を確保するために設定。
- tol
- 収束判定の許容誤差。誤差がこの値以下の変化になれば収束とみなす。
- verbose
- 学習過程の詳細情報を表示するかどうか。
- warm_start
- 前回の学習結果を保持して新しい学習を継続できるようにする設定。
- momentum
- SGDソルバ時のモーメンタム係数。過去の勾配を踏まえて更新を滑らかにする。
- nesterovs_momentum
- Nesterov momentumを使用するかどうか。
- early_stopping
- 訓練中に検証データで早期停止を行う機能。
- validation_fraction
- early_stopping を有効化した場合、検証データに充てる訓練データの割合。
- beta_1
- Adamオプティマイザの第一モーメント係数(過去の勾配情報の重み付けに関与)。
- beta_2
- Adamオプティマイザの第二モーメント係数。
- epsilon
- Adamオプティマイザの数値安定化のための微小値。
- power_t
- learning_rate が 'invscaling' の場合の減衰指数。
- n_iter_no_change
- 改善が見られなくなったときの待機回数。
インターネット・コンピュータの人気記事