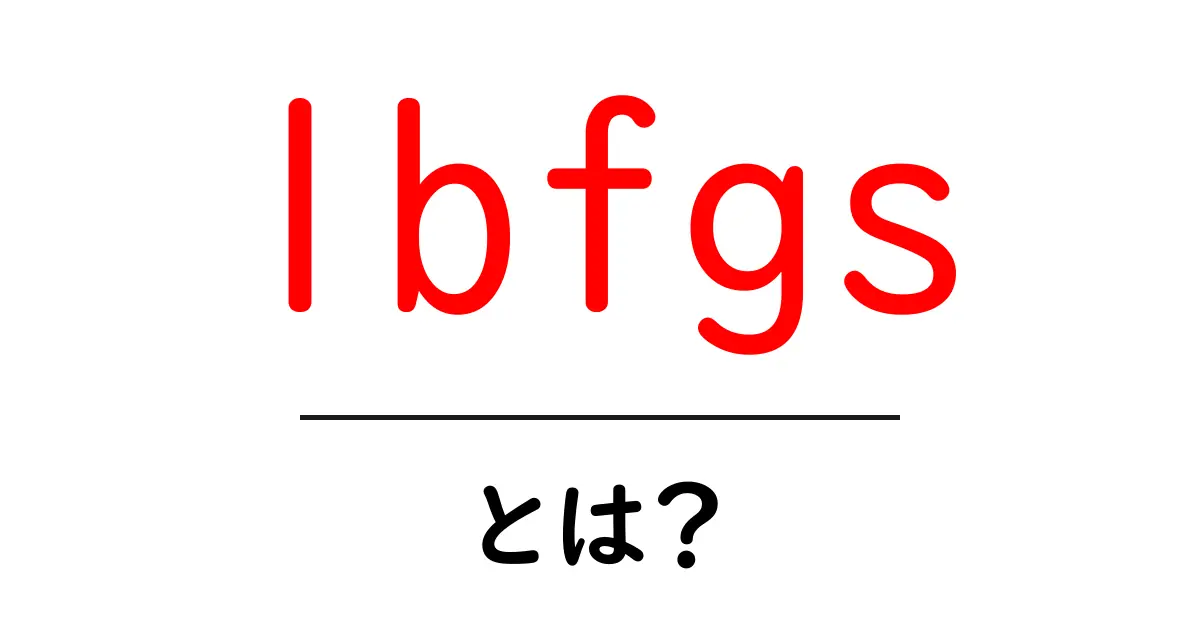

高岡智則
年齢:33歳 性別:男性 職業:Webディレクター(兼ライティング・SNS運用担当) 居住地:東京都杉並区・永福町の1LDKマンション 出身地:神奈川県川崎市 身長:176cm 体系:細身〜普通(最近ちょっとお腹が気になる) 血液型:A型 誕生日:1992年11月20日 最終学歴:明治大学・情報コミュニケーション学部卒 通勤:京王井の頭線で渋谷まで(通勤20分) 家族構成:一人暮らし、実家には両親と2歳下の妹 恋愛事情:独身。彼女は2年いない(本人は「忙しいだけ」と言い張る)
lbfgs・とは?
lbfgsは、機械学習やデータ解析で使われる「最適化アルゴリズム」です。正式には Limited-memory Broyden-Fletcher-Goldfarb-Shanno という名前の略で、しばしば L-BFGS や lbfgs と呼ばれます。最適化とは、ある数式の中で 最小の値を見つける作業のことです。機械学習では、コスト関数と呼ばれる指標を小さくする点を見つけることで、モデルの性能を上げることができます。
lbfgsの大きな特徴は、「少ない記憶で良い近似を作る」点です。従来のBFGSは全ての勾配情報を使って逆 Hessian 行列を更新しますが、lbfgsは更新に使う情報を制限します。これにより、変数の数が大きい場合でも必要なメモリを抑えて高速に動かせます。 imagine 大きな地図を作るとき、全ての道を覚えるのは大変です。lbfgsは直近の数回の経験だけを覚えて、全体の地形を推測します。これが「リミテッドメモリ」の意味です。
仕組みの要点は次のとおりです。lbfgsは勾配と過去の小さな情報を組み合わせて、最適解に向かう方向を決めます。通常の勾配降下法よりも賢く進み、二つの計算ループを使って新しい近似値を作ります。これにより、計算量を抑えつつ正の定義を保つ近似を維持できます。
実装や利用例としては、PythonのSciPyやPyTorchなどで lbfgs 相当のアルゴリズムを使う場面が多いです。SciPyの optimize.lbfgs に近い動作をすることが多く、PyTorchの LBFGS オプションも同様の考え方で動作します。これらのツールは、勾配関数を事前に用意しておく必要があります。勾配とは、関数がどの方向に進むと値が早く小さくなるかを教えてくれる「斜面の情報」です。
lbfgs の使い方と流れ
1) 初期値 x0 を決める。モデルのパラメータが入る領域を0やランダムな値で与えます。
2) 勾配関数を用意する。コスト関数の各パラメータに対する偏微分を計算できる関数を用意します。
3) 更新の回数や収束条件を設定する。勾配の大きさが小さくなるか、最大反復回数に達するかを判定します。
4) lbfgs のアルゴリズムを実行する。内部では最近の数回の勾配情報を使って新しい検索方向を決め、最小値を目指してパラメータを更新します。
5) 収束判定をクリアすれば終了。結果として得られたパラメータでモデルを評価します。
メリットは、大規模な問題でもメモリ消費を抑えつつ良い収束性を得られる点です。デメリットは、勾配がノイズに弱い場合や、目的関数が非滑らかな場合には最適解に到達しにくいことがある点です。また、適切な初期値や正則化の設定が必要になることもあります。
lbfgs の代表的な実装例としては、SciPyの optimize.lbfgs や、PyTorchの LBFGS optimizer などがあります。これらは連続で滑らかな関数に対して強い性能を発揮し、機械学習のパラメータ調整や科学計算の最適化でよく用いられます。
表: lbfgs の特徴と使い所
| 特徴 | リミテッドメモリで動作。n が大きい場合でも適切に動く。 |
|---|---|
| 用途 | 大規模な連続最適化や機械学習のハイパーパラメータ調整に適している。 |
| メモリ | 従来のBFGSより少ないメモリで近似を作る。 |
| デメリット | ノイズの多い勾配や非滑らかな関数には弱い。初期値や設定次第で結果が変わる。 |
よくある誤解と補足
lbfgsは「必ず最小値へ導く魔法の道具」ではありません。滑らかな関数で安定して動く一方、噪音が多いデータや高いノルムの制約がある場合には別のアルゴリズムを選ぶ方が良いこともあります。実務では、問題の性質に応じて他の最適化アルゴリズム(例: Adam、SGD、LBFGS-B など)と比較して選ぶのが良いです。
まとめ
lbfgsは大規模な最適化問題に強い、メモリ効率の良いアルゴリズムです。従来のBFGSと比べて記憶領域を抑えつつ、勾配情報を活用して効率的に解を探します。使い方は勾配関数を用意して初期値を決め、収束条件を設定するだけとシンプルですが、実際にはデータの性質や問題設定によって結果が変わる点に注意が必要です。
lbfgsの同意語
- L-BFGS
- 大規模な最適化問題で多用される、過去の勾配情報と現在の勾配情報を用いてヘッセ行列を近似する、有限メモリの準ニュートン法の一種です。
- LBFGS
- L-BFGS の表記ゆれ。限定メモリ版の BFGS アルゴリズムで、メモリ消費を抑えつつ高速に収束を目指します。
- 有限メモリBFGS法
- L-BFGS の直訳。大量変数の最適化で、過去情報を限定数だけ保持して更新します。
- 限定メモリBFGS法
- L-BFGS の日本語名称の一つ。過去の勾配差分と勾配を一定数のみ使って近似を更新する準ニュートン法。
- 限定メモリ準ニュートン法
- 準ニュートン法のうち、情報を限定してメモリ使用量を抑えるタイプ。L-BFGS が代表例です。
- 有限メモリ準ニュートン法
- 同義語。L-BFGS の別表現で、有限のメモリで近似を更新します。
- Limited-memory Broyden-Fletcher-Goldfarb-Shanno アルゴリズム
- L-BFGS の正式名称。BFGS の有限メモリ版。
- 有限メモリの BFGS アルゴリズム
- 日本語表現。有限メモリで近似を更新する BFGS アルゴリズム。
- finite-memory BFGS
- 英語表記。Limited-memory BFGS の別名。
- finite-memory quasi-Newton method
- 準ニュートン法の一種で、メモリを有限に抑えたアルゴリズム。L-BFGS はこのカテゴリに含まれます。
lbfgsの対義語・反対語
- グローバル最適化アルゴリズム
- LBFGSは局所的に速く解を見つける準ニュートン法ですが、対義語として解空間全体を探索してグローバルな最適解を狙うアルゴリズムを挙げます。代表例にはシミュレーテッドアニーリング、遺伝的アルゴリズム、粒子群最適化、全探索などが含まれます。
- フルメモリBFGS
- LBFGSが限られたメモリでヘシアンの近似を扱うのに対し、対義語として全てのヘシアン情報を保存して更新する従来のBFGS(フルメモリ版BFGS)を指します。メモリ使用量は多いですが、近似精度が高い場面もあります。
- 勾配降下法
- ヘシアンの近似を使わず、勾配の方向へ一定量だけ進む単純な最適化法。実装が簡単で計算コストが少ない一方、収束速度や学習率の設定次第でLBFGSより遅くなることがあります。
- 全ニュートン法
- LBFGSが近似ヘシアンを用いるのに対し、全ニュートン法はヘシアンを厳密に計算して更新します。計算コストが高い一方で収束性が安定する場合があります。
- 局所最適化
- LBFGSは局所的な最適解を素早く求めることが多いため、対義として全体最適を狙うグローバル最適化の概念と結びつきます。局所解に依存する性質を対比します。
- 全探索法
- 解空間を全て調べて最適解を保証する方法。計算量が爆発的に増えるため現実的には難しいことが多いですが、グローバル最適解を確実に求めるという意味でLBFGSの効率性とは対極に位置づけられます。
lbfgsの共起語
- lbfgs
- リミテッドメモリBFGSの略称。大規模な最適化で用いられる準ニュートン法の一種で、過去の勾配と更新情報を限定的に保存してヘッセ行列の近似を更新します。
- L-BFGS
- LBFGSと同義の英語表記。有限メモリのBFGSアルゴリズムを指す略称。
- LBFGS
- LBFGSの表記揺れのひとつ。有限メモリの準ニュートン法を指します。
- 準ニュートン法
- ニュートン法の近似版で、ヘッセ行列の逆行列を厳密には求めず、近似を用いて更新方向を決定する最適化手法。
- ヘッセ行列の近似
- 二階微分情報を厳密には計算せず、勾配の変化からヘッセ行列の近似を構築して更新方向を決定する手法。
- 逆ヘッセ行列
- ヘッセ行列の逆行列の近似。勾配とこの近似を組み合わせてパラメータを更新します。
- ヘッセ行列
- 二階微分情報をまとめた行列。最適化で局所の曲率を表します。
- 有限メモリ
- LBFGSが過去の勾配・更新情報を限られた量だけ保存して近似を更新する特徴。メモリ効率を高めます。
- 逆ヘッセ行列近似
- ヘッセ行列の逆行列の近似を指し、勾配の方向とスケールを決める鍵になります。
- 逆ヘッセ行列の近似更新
- 過去の情報を用いて逆ヘッセ行列の近似を更新する手順。
- 線探索
- 更新後のステップ長を適切に選ぶ探索手法。LBFGSでよく併用されます。
- バックトラックライン探索
- 線探索の一種で、目的関数の値が十分に減るまでステップ長を段階的に下げます。
- 収束判定
- 勾配の大きさや目的関数の変化量などを基に、最適化の収束を判断する基準。
- 収束速度
- 最適解へ到達する速さ。LBFGSは多くのケースで比較的速い収束を示します。
- 初期値
- 最適化の開始点。初期値が収束性や解の質に影響するため重要です。
- 初期ヘッセ近似
- 初期段階で用いるヘッセ行列の近似。通常は単位行列を用いることが多いです。
- 境界条件 / ボックス制約
- L-BFGS-Bが扱える、パラメータに上下限を設定する制約。制約付き最適化に対応します。
- SciPy
- Pythonの数値計算ライブラリ。最適化機能としてlbfgsを含むことが多く、SciPy.optimizeでよく使われます。
- SciPy.optimize
- SciPyの最適化モジュール。minimize関数で method='LBFGS' を指定して利用します。
- PyTorch
- 深層学習フレームワーク。LBFGSオプティマイザを提供し、ニューラルネットの訓練にも使われます(closureが必要なケースが多い)。
- ニュートン法
- 二階微分情報を用いる古典的な最適化法。LBFGSはこの理論を近似的に実現する手法です。
- 勾配
- 目的関数の一階微分。LBFGSの更新方向計算の基礎となる重要な情報です。
- 勾配計算
- 勾配を計算する方法。自動微分が主流で、LBFGS実装でも頻繁に利用されます。
lbfgsの関連用語
- lbfgs
- リミテッドメモリ BFGS。大規模な最適化問題でヘッセ行列の逆行列を近似する方法。過去数回の更新だけを保持してメモリを節約する。
- L-BFGS
- L-BFGSはlbfgsと同義で、メモリを制限した準ニュートン法の代表的なアルゴリズム。大規模データの学習にも向く。
- BFGS
- Broyden–Fletcher–Goldfarb–Shanno法のことで、準ニュートン法の一つ。逆ヘッセ行列の更新を行い、効率的に最適解へ進む。
- 準ニュートン法
- ニュートン法の計算負荷を抑えつつ、二次近似を使って最適化する手法の総称。ヘッセ行列の近似を利用する。
- ヘッセ行列
- 関数の二階微分からなる行列で、曲率を表す。最適化の収束を決める重要な情報。
- 逆ヘッセ行列
- ヘッセ行列の逆行列の近似。探索方向を決定する際に使われる。
- s_k
- x_{k+1} - x_k など、反復間の変位ベクトル。過去の更新情報として保存される。
- y_k
- 勾配 g_{k+1} - g_k の差分。過去の勾配変化を表す。
- 二回ループ法
- L-BFGSで使われる計算手順。過去のs_kとy_kを2回のループで組み合わせて逆ヘッセを計算する。
- ラインサーチ
- 新しい点の探索で適切なステップサイズを選ぶ手法。過大・過小の両方を避ける役割。
- Wolfe条件
- ラインサーチ時に満たすべき減少と曲率の条件。適切な収束と安定性を確保する。
- Armijo条件
- ラインサーチの減少条件の一つ。関数値が十分に減少することを保証する。
- 収束判定
- 勾配ノルムや目的関数の変化量などを用いて解が十分安定かどうかを判断する基準。
- 境界制約(L-BFGS-B)
- 変数値の取りうる範囲を事前に設定できる、境界制約付きのL-BFGSの拡張。
- 境界制約
- 変数の下限・上限を設定して解を制限する仕組み。L-BFGS-Bで実現可能。
- SciPy
- Pythonの科学計算ライブラリ。最適化モジュールでL-BFGS-Bを簡単に使える。
- PyTorch LBFGS
- PyTorchの最適化アルゴリズムの一つ。ニューラルネットの学習にも使われることがある。
- メモリ制限
- L-BFGSの特徴。過去の更新だけを保存して、メモリ使用を抑える設計。
- 非線形最適化
- 目的関数が非線形の場合に適用される最適化。LBFGSはこれに強い。
- 局所最適と大域最適
- LBFGSは局所解に収束しやすい性質があり、初期値に影響を受けやすい点に注意。
- 学習率/ステップサイズ
- 更新の大きさを決めるパラメータ。ラインサーチで適切な値を選ぶことが多い。
lbfgsのおすすめ参考サイト
学問の人気記事



















